Troubleshooting: a skill that never goes obsolete
Much of what I do, in multiple fields, could be reduced to one skill: troubleshooting.
I’ll define troubleshooting as systematically determining the cause of unwanted behaviour in a system, and fixing it.
Troubleshooting is often learned tacitly, in the process of explicitly learning “the skill”. Troubleshooting is rarely discussed as a skill unto itself. But many features of an effective approach to troubleshooting are domain-agnostic.
Realizing that I spend more time troubleshooting than I do building or doing, and that the skill of troubleshooting can be honed separately from the domain it’s applied to, I decided to try to figure out how to improve my troubleshooting skills — and as a result, my effectiveness in multiple domains.
The way I do it, troubleshooting mostly boils down to scratching my head, Googling the error message, and thinking up and testing hypotheses to narrow the search space. But I frequently catch myself making errors I have made before. So here’s what I try to remember when I’m troubleshooting, to keep myself on track and avoid dead-ends.
Step 1: step back
Troubleshooting takes a certain mind-set. It takes, as far as I can tell, an interest in the underlying structure of the system — “classical” thinking, to use Pirsig’s term — patience, attention to detail, and tenacity.
It’s sometimes more effective to approach troubleshooting slowly, thoughtfully, meditatively, even when in a hurry.
It’s easy to get lost in reactive problem whack-a-mole without stopping to think: what’s the real cause of this issue? What, exactly, is going on here?

The troubleshooter is part of the system. Hence, probe effects and the legendary heisenbug.
Make sure you’re tuning the right string
Anyone who’s played guitar for a while knows the visceral feeling of realizing they’re turning the tuner of a different string than the one they’re plucking. No wonder nothing is helping!
When trying to fix a system, before setting to work, I do something that’s guaranteed to have an effect.
If I think I know which wire to cut, I pull on it first to make sure it moves at the other end.
When I’m troubleshooting a CSS bug, I often start by setting * {color: red !important;}, so that I know the code I’m writing is in the right file, and is actually getting run!
Determine the flows

It’s easy to spend a lot of time trying to “fix” the problem. But that’s the easy part. The hard part is understanding the system, and then isolating and understanding the problem.
I usually start with how the “stuff” — electricity, water, gasoline, air, force, data, sewage, or whatever it is — flows through the system, and is transformed into different stuff in the process.
What are the inputs, outputs, and transformations? Can the different types of stuff flowing through the system be grouped into semi-distinct subsystems?
In an electrical system, it’s often helpful to physically trace the wiring. In mechanics, the same applies to pipes that carry liquid or gas, or to control cables, cams, gears, chains, and other items that conduct mechanical force. In software, trace the data. In social dynamics — good luck!
Observe the symptoms
What’s supposed to be happening here, what’s actually happening, and where do the two diverge?
If possible, I narrow down which subsystem(s) are affected based on the symptoms. If my car’s brake light isn’t working, the problem is likely electrical; if there’s an oil slick under the car, it’s probably not an electrical problem. If the engine won’t start, it could go either way, and more investigation is needed.
The belief that I understand the system is often a barrier to troubleshooting. Even if I “know the system inside out”, I’m unlikely to fully understand it. Even systems I built are composed of systems I didn’t; and even seemingly simple systems are infinitely complex. (As Carl Sagan put it: “If you wish to make an apple pie from scratch, you must first invent the universe.”)
Isolate the problem

The next step is to figure out what step the subsystem is failing at.
My basic approach: “doing science” on the system.
- Form a hypothesis about the problem. This can be an intuitive first impression from the symptoms, or a best guess from extended observation.
- Rule out the easiest and most likely problem areas first. Things that are meant to be serviced, have failed before, or are subject to mechanical stress. Good systems are designed to make what’s likely to break easy to service. Examples: electrical fuses & circuit breakers, belts and chains, filters, terminals and connections of all kinds, I/O devices.
- If there’s no easy way to guess which area of the system the problem lies in, perform an informal binary search.
- Find the simplest way to falsify my hypothesis. Generally, this means “cutting” the system immediately upstream/downstream of where I think the problem is, and testing for functionality at the cut-points.
Disconnect the subsystem
When possible, I disconnect the subsystem I’m debugging.
This has three benefits:
- It prevents weird interactions with the rest of the system from complicating the diagnosis (once I get the subsystem working on its own, I can connect it back together and see if it keeps working)
- It protects the rest of the system from my stupidity
- It often shortens the feedback loop
Or not
If I can’t (or don’t want to) fully disconnect the pieces, another approach is to probe — or cut and probe — at different points.
If I know or can intuit the acceptable range for the parameter in question at the test-point when the system is functioning correctly, the actual value can indicate the location of the problem.
Find good cut points
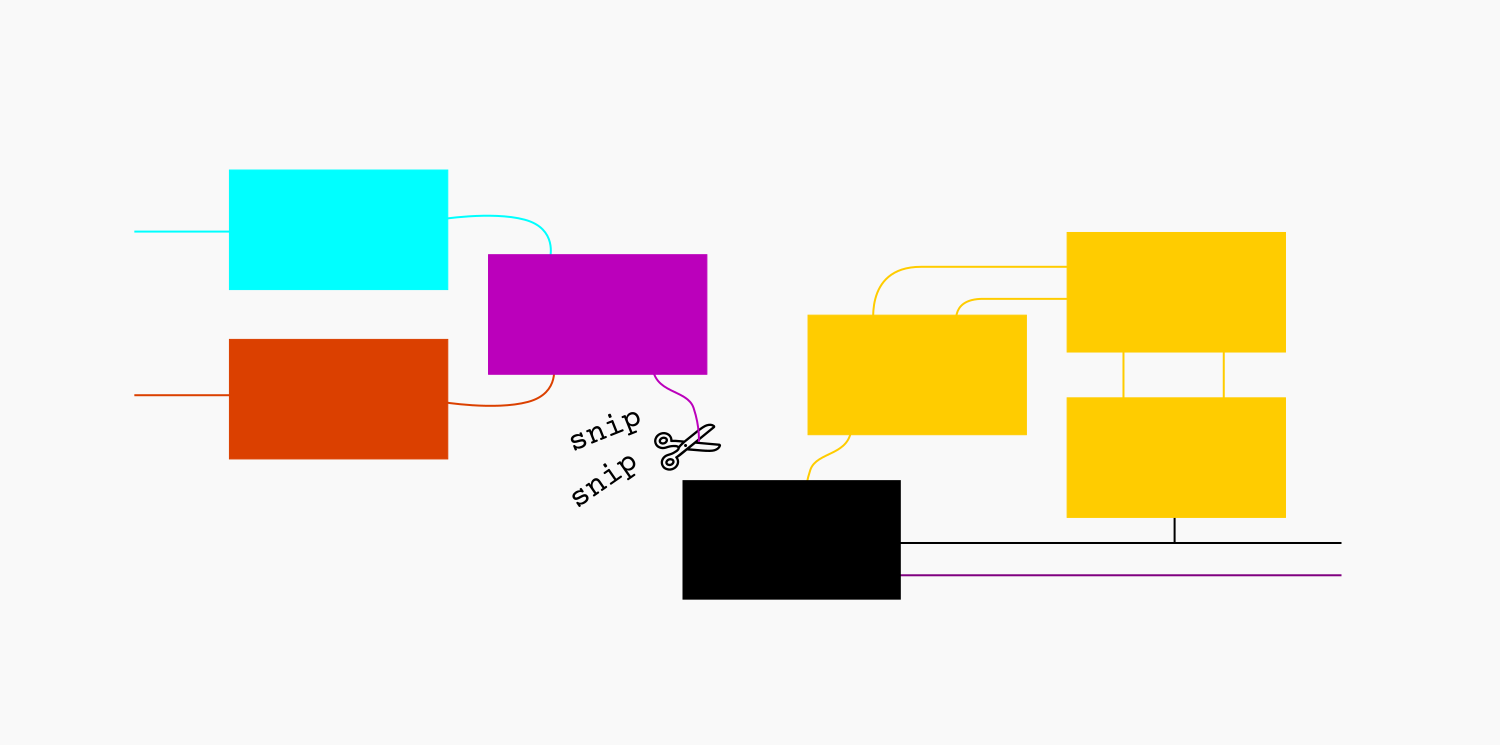
How many points can I “cut” the system at while maintaining functionality to test?
A spark plug is an example of a cut-point between subsystems.
If an engine won’t start, but I can get a spark, the problem probably isn’t in the electrical subsystem.
In additional to internal cut points, I always try to test at the interface between the system I’m responsible for and the rest of the world. This helps me figure out if “my stuff” is broken, or just getting fouled up trying to interact with “other people’s stuff” that’s broken (which it may or may not be within my power to fix). Trying to fix something that has nothing wrong with it can chew up a lot of time!
Balance getting informed, and attempting fixes
How much effort should be put into attempts to fix the problem, and how much effort should be put into getting information about the problem?
If my intuition’s right, jumping right into fixing the problem is way faster.
But if it isn’t, systematically gathering information is more efficient in the long run.
We go into troubleshooting situations with a prior about the hardness of the problem we’re facing, and this informs when we try to jump in and fix the problem, and when we try to gather more information about it.
But often our “hardness prior” is wrong. So we need to develop some kind of meta-prior about how accurate our troubleshooting hardness prior is likely to be, based on our personal tendency, and domain expertise.
Know the stakes
The stakes for troubleshooting problems can range from zero (hobby software project), to life-altering (medical diagnosis), to existential (AGI, nuclear weapons), and this should inform how the problem is approached.
So I try to ask myself:
-
What’s the worst thing that could happen? What are the risks if I screw up? And, what are the chances that I’ll screw up?
- Danger to troubleshooter: How dangerous is the system to work on? Is there high voltage, inflammable materials, toxic chemicals, jack-alls, or possible data loss involved?
- Danger to bystanders: Same as above, but factoring in the size of the blast radius, and the bystanders’ potential ignorance of danger and lack of safety equipment.
- Danger to system: How delicate is this system? Is it replaceable?
- Danger to others: What are the possible consequences of this system behaving unpredictably? Who is downstream from this system?
-
What are the comparative risks of attempting a fix, and not attempting a fix?
- If something is already dangerously broken, repairing it is comparatively safer, even if repairing it has risks of failure.
-
Who does the system belong to?
- Did I break this system? Am I responsible for fixing it?
- Am I getting paid to fix it? If so, what are my chances of success, failure, and catastrophic failure, and does the client know the risks? (I no longer do volunteer tech support for people who haven’t backed up their system.)
-
How can I reduce downside risk of this intervention?
- Generally, working more slowly and carefully (so I don’t screw up); working on a “staging” rather than “live” system; backing up the system.
Danger, in this case, has at least four components: timeframe, intensity, reach, and physicality. The most obvious dangers are immediate and physical. But as far as harm/benefit, working on critical code for a major investment bank may be in the long run as physically risky; the risk is just distributed, deferred, and invisible.
- A hobby software project might have long-term upside or downside risk, but in the short term, tends to have few people downstream, who don’t rely on it, and aren’t particularly affected by it, physically or otherwise.
- Car brakes are moderately dangerous to work on, but if you screw up, everyone on the highway (and everything they’re responsible for) is put at risk.
- If my car has quit at dusk in a sketchy neighbourhood, jerry-rigging the battery might be safer than wandering around trying to find a hotel and a mechanic.
- Making a medical diagnosis has immediate, potentially life-altering stakes for one person. Working on medical software has deferred life-altering stakes for many, many more people. Influencing foreign policy or nuclear strategy has deferred life altering stakes for some or all of the planet.
Don’t overthink it
Don’t assume it’s complicated. Just because it’s complicated to debug doesn’t mean that the cause is complicated.
But don’t assume it’s simple, either.
Be patient
Enough said.
Find information about the system.
By definition, a troubleshooter is out of their depth. Good troubleshooters have to get used to being in a state of ignorance.
What information is needed, and how to get it, varies based on the details of the system and problem.
Knowing what search engine to use for what kind of information
Sometimes (with, say, mechanics, or failing to catch fish) I need to know someone who knows how to do it, and bring them a case of beer.
Other times, I need to know how to use libraries or manuals. (Case study: the electric windows on my mother’s Subaru stopped working. Various car people tried to fix them. I checked the fuses. But she was the one who had the brilliant thought of reading the manual rather than just skimming it to find out about the fuses. The child safety lock was on.)
In the modern world, I mostly need to know how to use search engines. Different search engines are useful for different purposes, and Google no longer seems to index many niche sites.
I might need an LLM because I don’t know how to phrase my question in the right terminology, search a domain-specific forum to cut the fluff, search YouTube if it’s a physical skill that’s hard to describe verbally, or directly search the documentation/manual of the system in question.
Knowing how to narrow the search space with advanced search criteria
Though none of them are troubleshooting-specific, here are three articles to get started if you aren’t familiar with search operators:
⇒ How to find anything on the Internet (Google specific, by example)
⇒ Google Search Operators: The Complete List (44 Advanced Operators) (Google-specific, more complete, marketing focussed)
⇒ Internet Search Tips (Exhaustive, academically focussed)
Knowing how to widen the search space & tune out irrelevant information
Most systems emit information of many kinds, and of widely varying relevance.
In software logs, there are lines and lines of repetitive chatter, and then one line that tips me off. Usually, it will say “error” or “fail”, or mention the affected subsystem.
Similarly, engines make a lot of noise. Most of the noise is normal. The relevant data is what changed about the sound. When the expected noise is subtracted from total noise, what’s left? The sonic fingerprint of the problem.
Only some parts of the error message itself matter.
Most software error messages will turn up very little useful in Google if I paste them verbatim, because they include things specific to my device. I generally start with the full error message, minus obviously device-specific info. If nothing turns up, I widen my search space. I stop looking for info about the specific version. I stop looking for info about the specific hardware. I stop looking for info about the specific software, even, and then I find people in the forums who have a different laptop, running a different app, that shares the dependency that’s causing the error. Their fix might not work, but it might point me to what the problem is. Then I can get more data and repeat the process.
Learning to fish
If something needs repair, I can try to do it myself, which can be slow and inefficient. Or I can get an expert to do it, which is fast and easy. The catch with getting someone else to solve my problem: I don’t learn much.
If I have a troubleshooting problem, and I’m clueless about the domain, a highly effective approach can be to:
- Find a domain expert for the type of system/problem
- Rather than having them fix it for me, get them to fix it with me.
This is slower and sometimes less fun for both parties, in the short term, but a lot can be learned. And next time I might be able to do it myself.
It’s a continuum, with watching them fix it on one end, and fixing it myself while they watch on the other. The more hands-on I am, the slower and more frustrating it is for everybody — and the more I’m forced to learn.
Get information from the system

The more information I get from the system, preferably as the error is occurring, the better.
I get all the information I can from the system: more output, and more specific output, from more points in the system.
In software, that means logging, or attaching a debugger to the process while it’s running.
In electronics, the first step is usually to get a multimeter, and check for the state of the system at different points.
In mechanics, which I’m not very good at, I’ve noticed my older brother generally runs the thing with the hood open, while watching, smelling, and listening closely.
Eric Barker writes about this in relation to people in Plays Well With Others. We’re bad at reading people (even when we think we aren’t), and one of the few things that helps is to interact with the person in a way that generates more information. “Getting more information from the system” is among the few scientifically-validated methods of lie detection (liars eventually contradict themselves). Relatedly: many people can talk authoritatively on complex subjects, but two or three well-chosen questions that drill into the details can separate the real experts from those who are just repeating other’s surface-level opinions to sound impressive.
When we’re debugging ourselves, the mere act of getting information from the system (journaling) sometimes mostly fixes it.
Intuit the tolerances of the system
Sometimes, in the process of fixing things, we break stuff, accidentally or because it can’t be helped.
Different materials have different tolerances. Certain parts can incur certain kinds of damage without changing the functionality of the system. Other areas might cause the whole system to fail if they’re treated the same way.
With physical things, it takes mechanical intuition to apply the right amount of force, and understand what parts can and cannot withstand damage. A bore, or a seal, is more sensitive than the outside casing.
Have a good relation to the system
I’ve noticed: people who dislike their computers tend to be ineffective with computers; and people who dislike people tend not to get what they want from them, unless they’re good at hiding their feelings. It sounds wishy-washy, but I think appreciating the beauty and complexity of the system that’s misbehaving makes one a more effective troubleshooter. Treating the system as an enemy makes it one.
In my mind, an enemy is distinct from an opponent. Friendly competition with the system, trying to “beat it at the game”, doesn’t seem to impair troubleshooting. Opponents must be respected and understood to be beaten. It’s the “bad dog” stupid-computer-won’t-do-what-I-want mentality that’s to be avoided. Enemies, when hated, are stripped of their individuality, and become a caricature of themselves; and you cannot troubleshoot a caricature, because it does not map to the actual system.
Anecdotally, I know two local mechanics. One of them swears and bangs things and sometimes throws tools around. He is nicknamed “Angry [Name Redacted]”. He is the inexpensive mechanic. Another tells stories of fixing Toyotas with duct tape and women’s stockings. Everyone I know, regardless of their opinion of him, respects his skills as a mechanic. Talking to him gives the impression that he loves cars, and takes delight in working with them. He is considered the best mechanic in the area; he’s also the most expensive.
Make do with what’s available
It helps to have the correct tools to test, disassemble, repair, and reassemble the system.
In practice, it’s usually more important to be able to improvise, and find both tools and replacement parts based not on labels or preconceptions, but on underlying form.
Shorten the feedback loop
In order to fix a system, I need to be able to reproduce the problem. In order to get enough data about the cause of the problem to reproduce it reliably, I often need to run the system multiple times under different conditions. Then, once I can reproduce it, I often need to run the system a bunch more times, tweaking the parameters each time, trying to sus out what aspect of the conditions is actually triggering the problem.
Sometimes, a system will have some built-in delay or latency, making it difficult to reproduce the error without a complicated set of steps.
When this is the case, I ask, “is there any way I can shorten the feedback loop?”
In code, it might be reducing a hard-coded timeout, working on just the subcomponent (with dummy input and output), testing it locally so I’m not hitting the network, enabling hot-reloading, or automating the deployment process.
With electronics, it might be as simple as taping the multimeter to the terminals.
A somewhat pathetic example: when troubleshooting, I often find myself looking stuff up on a tiny phone with a slow connection, or going back and forth between the thing I’m fixing and the source of information about the thing I’m fixing. Propping up the manual or computer right where I’m working can be surprisingly time-saving.
Reduce noise
Before performing an intervention, I try to reduce confounding variables and “slop” in the system.
Disconnecting the subsystems helps with this, because interactions with other subsystems can confuse the results of tests.
Shortening the feedback loop can help, because a time delay gives a chance for other variables to affect the state of the system between when the input goes in and when the output comes out.
Write it down
Writers are fond of saying that “writing is thinking”. Here are two ways I use writing as a troubleshooting tool:
-
Rubber duck debugging like a pro: I can often solve my problem by drafting a forum post without posting it. The effort required to articulate the salient details of the system and the problem, without looking dumb, is higher than the effort I have usually put in at the point I decide I need help. Corollary: making a forum post without sounding like I haven’t done my homework also tends to put me over my time/energy budget for solving a seemingly-trivial problem.
-
Behold the trail of crumbs: I find that writing and diagramming, while helpful for many troubleshooting projects, are essential for multi-session troubleshooting projects. I overestimate how much I will remember about the context, as well as how soon I will get around to continuing the project. A troubleshooting notes file, no matter how obvious or incomplete the information in it seems at the time I write it, leaves a trail of crumbs that I can follow next time. (I have often repeated, verbatim, an entire troubleshooting process, found the problem — and then remembered I troubleshot the exact system, and arrived at the same conclusion, years ago; but there was some hiccup, and I failed to order or install the new part.)
Look inside black boxes by dropping weirdly-specific things into them and watching what comes out
“Disconnect the subsystem” notwithstanding, sometimes I have to troubleshoot black-box systems. One way to do so is to feed them very specific input, and watch what happens. If a system fails on certain input, it can be helpful to take one of two approaches:
-
Take the conditions/input that caused it to fail, remove a component of the condition/input, and feed that into the system. If it still causes the problem, remove another factor (optionally, restoring the previous factor). Repeat until all that’s left is the thing that’s really causing the problem, or as close as I can get.
-
Take some known-okay conditions/input. Add one factor that was present in the failure-causing input/condition. Repeat (one by one, or additively) until the system fails.
Understanding the problem
Maybe one of the widgets is fried. But why is it fried? Is it normal that widgets just fry on a Tuesday afternoon? Or, is there a short circuit, or water damage, or heat dissipation issues, or (as in a recent case), a susceptibility to getting knocked out by nearby radar?
If something isn’t supposed to fail, and it failed, there’s more to the story.
Before I put in a new part, I want to be confident it won’t suffer the same fate. Either the previous part was under spec, or something else in the system is putting it under undue strain.
Fixing the problem
A problem that is understood is already mostly solved, unless parts are hard to come by, or hard to install.
“Fixing” something is generally a synonym for “swapping out the broken component.”
How well I understand the problem and the system determines how large a piece of the system needs to be replaced. “Part swapper” is a derogatory term for a bad mechanic. Generally, the better the troubleshooter, the smaller the component replaced.
These statements might all be true:
- This sound system is broken.
- This MP3 player is broken.
- The headphone jack on this MP3 player is broken.
- The solder joint on the headphone jack of this MP3 player is broken.
I can replace the MP3 player. I can replace the headphone jack. Or, I can reflow one solder joint. The results will be the same.
Although it’s wasteful and inelegant to replace more than necessary, a good troubleshooter also needs to know when to give up on getting to the root of a problem that doesn’t really matter, and settle for a more resource-efficient band-aid solution.
Sometimes I get to the root of the problem, and sometimes I don’t.
Can troubleshooting be taught?
I’ve been working on this essay, intermittently, since May 2024. Maybe I’m kidding myself, but I seem to have gotten better at troubleshooting. The biggest change is that now I bother. I take on otherwise-unappealing troubleshooting problems in order to test my theories, regardless of whether I consider them worth my time. And because of how much time I’ve spent thinking about and talking about troubleshooting, I feel like I should be some kind of local expert, and want to live up to that reputation even if it exists only in my mind.
If I had the budget, I would test this scientifically. I would recruit a bunch of people. Half of them would read this essay, and the other half would read something the same length and style that wasn’t about troubleshooting. Then, both groups would try to solve Linux server troubleshooting puzzles on a site like sadservers.com. Which group would be more effective? If the ones who read this essay did better, the experiment could be repeated in other domains, to see how well troubleshooting skills generalize. (A more entertaining and less rigorous possibility that I considered: pitching Wired magazine for a gonzo journalism story wherein I apply the advice in this essay to a bunch of troubleshooting problems in domains I’m embarrassingly clueless about.)
Conclusion
Once I get into the troubleshooting mindset, most things start to look like troubleshooting problems. This system-problem-solution way of seeing the world is effective in certain circumstances, but it’s not the only way of seeing the world, and it’s not the best approach for everything.
It saves a lot of time to realize when I’m dealing with a troubleshooting problem, and consciously troubleshoot it. But it’s equally important to realize not everything is a problem that needs a solution.
Here are some troubleshooting stories I’ve run across on the web:
- Car allergic to vanilla ice cream
- The Wi-Fi only works when it’s raining
- The case of the 500-mile email
- Money Well Spent: A short Story for Engineers
- Take care editing Bash scripts
Happy troubleshooting!
When I asked a Llama3 LLM to “List all spelling, grammar, and reasoning errors in this essay”, it produced a motley list of real and hallucinated errors, including “Oversimplification of complex systems (e.g., motorcycles)”, concluding:
Overall, while the essay attempts to provide some guidance on troubleshooting approaches, it is marred by numerous errors that detract from its clarity and effectiveness.
But perhaps you could help me troubleshoot this essay. Is there a key technique I’ve missed? Something I’ve included that you think is bogus? Leave a comment or send me an email.
Thanks to everyone who gave feedback on early drafts of this essay, or spent hours discussing troubleshooting with me. All errors are my own.
Special thanks to my older brothers, for granting access to the famous licorice tin of scavenged electronic components; building Van de Graaff generators, morse code telegraphs, pneumatic spitball shooters, seaweed cannons, autonomous robots, rockets, and spot welders with me; and making it possible for me to write (rather optimistically) in my journal at age ten: “Today I lerned PHP!!!”.